10亿+海关交易数据,1.2亿企业数据,2亿+企业联系人数据,1000千万真实采购商。覆盖200+个国家及地区,95%外贸重点拓展市场,可根据行业、经营范围等多方位挖掘目标客户。
免费试用BM25(Best Match25)是在信息检索系统中根据提出的query对document进行评分的算法。It is based on the probabilistic retrieval framework?developed in the 1970s and 1980s by?Stephen E. Robertson,?Karen Sp?rck Jones, and others.BM25算法首先由OKapi系统实现,所以又称为OKapi BM25。
BM25属于bag-of-words模型,bag-of-words模型只考虑document中词频,不考虑句子结构或者语法关系之类,把document当做装words的袋子,具体袋子里面可以是杂乱无章的。It is not a single function, but actually a whole family of scoring functions, with slightly different components and parameters. One of the most prominent instantiations of the function is as follows.
对于一个query?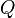
对每一个搜索查询,我们很容易给每个文档定义一个“相关分数”。当用户进行搜索时,我们可以使用相关分数进行排序而不是使用文档出现时间来进行排序。这样,最相关的文档将排在第一个,无论它是多久之前创建的(当然,有的时候和文档的创建时间也是有关的)。
有很多很多种计算文字之间相关性的方法,但是我们要从最简单的、基于统计的方法说起。这种方法不需要理解语言本身,而是通过统计词语的使用、匹配和基于文档中特有词的普及率的权重等情况来决定“相关分数”。
这个算法不关心词语是名词还是动词,也不关心词语的意义。它唯一关心的是哪些是常用词,那些是稀有词。如果一个搜索语句中包括常用词和稀有词,你最好让包含稀有词的文档的评分高一些,同时降低常用词的权重。
这个算法被称为?Okapi BM25。它包含两个基本概念 词语频率(term frequency) 简称词频(“TF”)?和 文档频率倒数(inverse document frequency) 简写为(“IDF”).?把它们放到一起,被称为 “TF-IDF”,这是一种统计学测度,用来表示一个词语 (term) 在文档中有多重要。
词语频率(?Term Frequency), 简称?“TF”, 是一个很简单的度量标准:一个特定的词语在文档出现的次数。你可以把这个值除以该文档中词语的总数,得到一个分数。例如文档中有 100 个词, ‘the’ 这个词出现了 8 次,那么 ‘the’ 的 TF 为 8 或 8/100 或 8%(取决于你想怎么表示它)。
逆向文件频率(Inverse Document Frequency), 简称?“IDF”,要复杂一些:一个词越稀有,这个值越高。它由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。越是稀有的词,越会产生高的 “IDF”。
如果你将这两个数字乘到一起 (TF*IDF), 你将会得到一个词语在文档中的权重。“权重”的定义是:这个词有多稀有并且在文档中出现的多么频繁?
你可以将这个概念用于文档的搜索查询。在查询中的对于查询中的每个关键字,计算他们的?TF-IDF 分数,并把它们相加。得分最高的就是与查询语句最符合的文档。
很酷吧!
上述算法是一个可用的算法,但并不太完美。它给出了一个基于统计学的相关分数算法,我们还可以进一步改进它。
Okapi BM25 是到目前为止被认为最先进的排名算法之一(所以被称为?ElasticSearch?)。Okapi BM25 在 TF-IDF 的基础上增加了两个可调参数,k1 和 b,, 分别代表 “词语频率饱和度(term frequency saturation)” 和 “字段长度规约”。这是什么鬼?
为了能直观的理解“词语频率饱和度”,请想象两篇差不多长度的讨论棒球的文章。另外,我们假设所有文档(除去这两篇)并没有多少与棒球相关的内容,因此 “棒球” 这个词将具有很高的 IDF – 它极稀少而且很重要。 这两篇文章都是讨论棒球的,而且都花了大量的篇幅讨论它,但是其中一篇比另一篇更多的使用了“棒球”这个词。那么在这种情况,是否一篇文章真的要比另一篇文章相差很多的分数呢?既然两个两个文档都是大篇幅讨论棒球的,那么“棒球”这个词出现 40 次还是 80 次都是一样的。事实上,30 次就该封顶啦!
这就是 “词语频率饱和度。原生的 TF-IDF 算法没有饱和的概念,所以出现 80 次“棒球”的文档要比出现 40 次的得分高一倍。有些时候,这时我们所希望的,但有些时候我们并不希望这样。
此外,Okapi BM25 还有个 k1 参数,它用于调节饱和度变化的速率。k1 参数的值一般介于 1.2 到? 2.0 之间。数值越低则饱和的过程越快速。(意味着两个上面两个文档有相同的分数,因为他们都包含大量的“棒球”这个词语)
字段长度归约(Field-length normalization)将文档的长度归约化到全部文档的平均长度上。这对于单字段集合(single-field collections)(例如 ours)很有用,可以将不同长度的文档统一到相同的比较条件上。对于双字段集合(例如 “title” 和 “body”)更加有意义,它同样可以将 title 和 body 字段统一到相同的比较条件上。字段长度归约用 b 来表示,它的值在 0 和 1 之间,1 意味着全部归约化,0 则不进行归约化。
在Okapi BM25 维基百科中你可以了解Okapi算法的公式。既然都知道了式子中的每一项是什么,这肯定是很容易地就理解了。所以我们就不提公式,直接进入代码:
BM25.Tokenize = function(text) {
text = text
.toLowerCase()
.replace(/W/g, ' ')
.replace(/s+/g, ' ')
.trim()
.split(' ')
.map(function(a) { return stemmer(a); });
// Filter out stopStems
var out = [];
for (var i = 0, len = text.length; i < len; i++) {
if (stopStems.indexOf(text[i]) === -1) {
out.push(text[i]);
}
}
return out;
我们定义了一个简单的静态方法Tokenize(),目的是为了解析字符串到tokens的数组中。就这样,我们小写所有的tokens(为了减少熵)。我们运行Porter Stemmer 算法来减少熵的量同时也提高匹配程度(“walking”和”walk”匹配是相同的)。而且我们也过滤掉停用词(很普通的词)为了更近一步减少熵值。在我所写的概念深入之前,如果我过于解释这一节就请多担待。
BM25.prototype.addDocument = function(doc) {
if (typeof doc.id === 'undefined') { throw new Error(1000, 'ID is a required property of documents.'); };
if (typeof doc.body === 'undefined') { throw new Error(1001, 'Body is a required property of documents.'); };
// Raw tokenized list of words
var tokens = BM25.Tokenize(doc.body);
// Will hold unique terms and their counts and frequencies
var _terms = {};
// docObj will eventually be added to the documents database
var docObj = {id: doc.id, tokens: tokens, body: doc.body};
// Count number of terms
docObj.termCount = tokens.length;
// Increment totalDocuments
this.totalDocuments++;
// Readjust averageDocumentLength
this.totalDocumentTermLength += docObj.termCount;
this.averageDocumentLength = this.totalDocumentTermLength / this.totalDocuments;
// Calculate term frequency
// First get terms count
for (var i = 0, len = tokens.length; i < len; i++) {
var term = tokens[i];
if (!_terms[term]) {
_terms[term] = {
count: 0,
freq: 0
};
};
_terms[term].count++;
}
// Then re-loop to calculate term frequency.
// We'll also update inverse document frequencies here.
var keys = Object.keys(_terms);
for (var i = 0, len = keys.length; i < len; i++) {
var term = keys[i];
// Term Frequency for this document.
_terms[term].freq = _terms[term].count / docObj.termCount;
// Inverse Document Frequency initialization
if (!this.terms[term]) {
this.terms[term] = {
n: 0, // Number of docs this term appears in, uniquely
idf: 0
};
}
this.terms[term].n++;
};
// Calculate inverse document frequencies
// This is SLOWish so if you want to index a big batch of documents,
// comment this out and run it once at the end of your addDocuments run
// If you're only indexing a document or two at a time you can leave this in.
// this.updateIdf();
// Add docObj to docs db
docObj.terms = _terms;
this.documents[docObj.id] = docObj;
};
(本文内容根据网络资料整理和来自用户投稿,出于传递更多信息之目的,不代表本站其观点和立场。本站不具备任何原创保护和所有权,也不对其真实性、可靠性承担任何法律责任,特此声明!)
OKapi BM25是一种非常流行的快速信息检索模型,它基于文档长度调整的TF-IDF模型。BM25算法考虑了查询词在文档中的频率和文档长度,同时也考虑了查询词在整个语料库中的频率等因素,能够很好地评估查询词在文档中的重要程度。
Q2:OKapi BM25 算法的公式是什么?OKapi BM25算法的概率得分公式为:
score(Q,D) = ∑_{t in Q} IDF(t) * TF(t in D) * (K1 + 1) / (TF(t in D) + K1 * (1 - B + B * |D|/avgdl)) * (K3 + 1) / (K3 + TF(t in D))
Q3:如何实现OKapi BM25 算法?要实现OKapi BM25算法,主要需要以下步骤:
1. 收集文本语料,统计每个词的TF和DF的值
2. 计算每个词的TF-IDF权重
3. 对查询词进行相关性匹配,计算每个文档的BM25得分
4. 对计算得分进行排序,取排名靠前的文档作为查询结果
Q4:OKapi BM25 算法的参数K1、B、K3的含义是什么?K1参数控制查询词在文档中的次数和其重要性之间的影响程度。B参数控制文档长度对查询词重要性的影响程度。K3参数控制长查询中的查询词重复次数对结果的影响。这三个参数需要根据实际情况进行调优,以取得最佳效果。

 印度尼西亚
印度尼西亚 越南
越南 印度
印度 菲律宾
菲律宾 土耳其
土耳其 美国
美国 墨西哥
墨西哥 加拿大
加拿大 危地马拉
危地马拉 歌诗达黎加
歌诗达黎加 阿根廷
阿根廷 巴西
巴西 智利
智利 哥伦比亚
哥伦比亚 秘鲁
秘鲁 俄罗斯
俄罗斯 乌克兰
乌克兰 法国
法国 德国
德国 意大利
意大利 埃塞俄比亚
埃塞俄比亚 乌干达
乌干达 博茨瓦纳
博茨瓦纳 加纳
加纳 肯尼亚
肯尼亚 澳大利亚
澳大利亚 新西兰
新西兰 斐济
斐济 维尔京群岛
维尔京群岛 关岛
关岛












